Wprowadzenie
Nie zawsze program MapReduce jest na tyle prosty, że pierwsza próba jego napisania kończy się sukcesem.
Co jeśli nasz program jest na tyle skomplikowany, że wymaga długotrwałej implementacji? Długotrwałe korzystanie z klastra może wiązać się ze znacznymi kosztami. W takim przypadku byłoby dobrze móc uruchamiać nasz program MapReduce lokalnie.
Duża część narzędzi Big Data posiada możliwość uruchamiania w tzw. trybie local. Tryb ten z reguły wykorzystuje wątki JVM analogicznie jak w przypadku klastra Hadoop wykorzystywane byłyby kontenery YARN.
Taki sam tryb ma MapReduce. W dawnych jego wersjach (org.apache.hadoop.mapred.*) uzyskiwało się go ustawiając po prostu parametr konfiguracyjny
conf.set("mapreduce.framework.name", "local");
W przypadku nowszych bibliotek stosowane podejście wygląda nieco inaczej. Gotowi?
Punkt wyjścia
Zaczniemy od początku.
- Utwórz projekt Javy w IntelliJ IDE o nazwie
WordCount
- Utwórz nową klasę Javy
WordCount
- Wprowadź do pliku tej klasy kod z dokumentacji Apache Hadoop
https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Example:_WordCount_v1.0
- Oczywiście brakuje nam kilku bibliotek. Przejdź do ustawień projektu na zakładkę Libraries
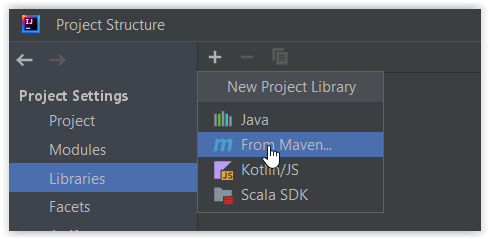
- A następnie dodaj następujące biblioteki
org.apache.hadoop:hadoop-common:3.3.5org.apache.hadoop:hadoop-mapreduce-client-common:3.3.5
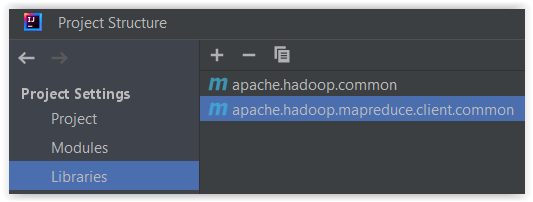
I tu dość istotna uwaga.
Standardowo biblioteką MapReduce, którą potrzebujemy jest org.apache.hadoop:hadoop-mapreduce-client-core:3.3.5
Jest ona właściwym rozwiązaniem jeśli chcemy uruchamiać zadania MapReduce w klastrach Hadoop, gdzie jest dostępny zarówno YARN jak i HDFS,
patrz: https://hadoop.apache.org/docs/r3.3.5/hadoop-mapreduce-client/hadoop-mapreduce-client-core/dependency-analysis.html
my skorzystaliśmy z biblioteki org.apache.hadoop:hadoop-mapreduce-client-common:3.3.5
która takich możliwości nie posiada,
patrz: https://hadoop.apache.org/docs/r3.3.5/hadoop-mapreduce-client/hadoop-mapreduce-client-common/dependency-analysis.html
Jednak w zamian za to posiada np. klasę org.apache.hadoop.mapred.LocalJobRunner i dzięki niej pozwala na bezproblemowe uruchamianie i testowanie zadań MapReduce w trybie local, jak będziemy mieli się okazję za chwilę przekonać.
- Pobierz przykładowe dane, które będziemy przetwarzali np.:
https://sherlock-holm.es/stories/plain-text/cano.txt
i umieść je w katalogu np.c:\tmp\input\ - Uruchom nasz program po raz pierwszy. Efekt nie będzie pozytywny

- Powód jest oczywisty. Nasz kod wymaga podania parametrów

- Wprowadźmy zatem zmiany w konfiguracji uruchamiania naszego programu. W założeniu katalog
c:\tmp\outputnie istnieje – będzie on utworzony przez zadanie MapReduce
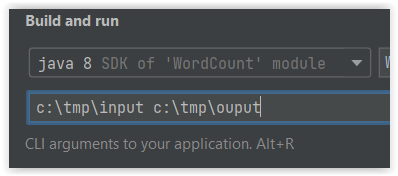
- Ponownie uruchom naszą aplikację.

i… jeśli masz ustawioną zmienną środowiskową HADOOP_HOME wskazującą na odpowiednie katalog domowy oprogramowania Hadoop to…
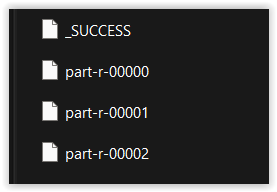
dane z katalogu c:\tmp\input zostały przetworzone, a wyniki umieszczone w katalogu c:\tmp\ouput
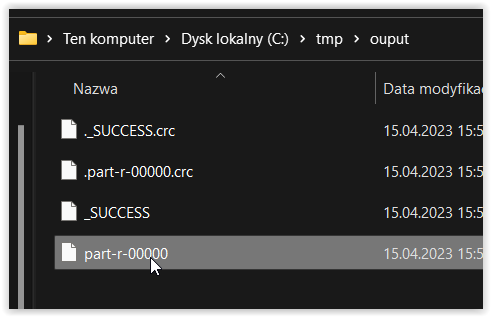
Jeśli jednak te zmiennej HADOOP_HOME nie posiadasz to rezultat jest zapewne podobny do tego poniżej

W takim przypadku potrzebny jest jeszcze jeden etap
Środowisko
W przypadku środowiska Linux wystarczy zapewne
- pobrać właściwą wersję oprogramowania Apache Hadoop https://hadoop.apache.org/releases.html
- rozpakować ją do wybranego katalogu, a następnie
- zdefiniować zmienną HADOOP_HOME
W przypadku środowiska Windows sytuacja jest nieco odmienna. Apache Hadoop nie jest przeznaczony dla środowiska Windows. Na szczęście stworzone zostało specjalne oprogramowanie winutils, które ten problem rozwiązuje.
- Pobierz odpowiednią wersję oprogramowania ze strony https://github.com/cdarlint/winutils
- Następnie ustaw/dodaj zmienną środowiskową
HADOOP_HOME, tak aby wskazywała na właściwy katalog.

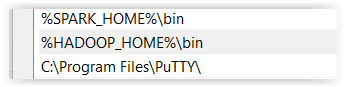
- Zmień też zmienną środowiskową
PATH, tak aby zawierała%HADOOP_HOME%\bin

- Zrestartuj IntelliJ IDEA, aby zmienne środowiskowe zostały ponownie zaczytane i… gotowe.
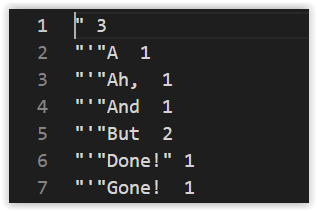
Dane z katalogu c:\tmp\input zostały przetworzone, a wyniki umieszczone w katalogu c:\tmp\ouput

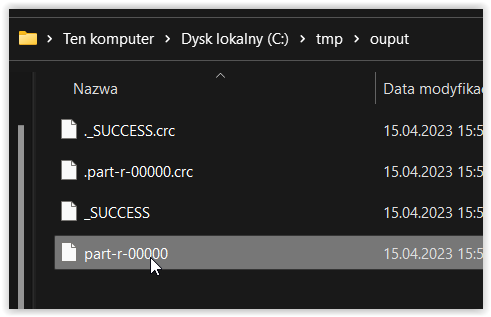
Uwaga! Domyślnie silnik MapReduce wykorzystuje jeden reduktor.
Patrz: https://hadoop.apache.org/docs/r3.3.5/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml

Pliki konfiguracyjne mogą to oczywiście zmienić.
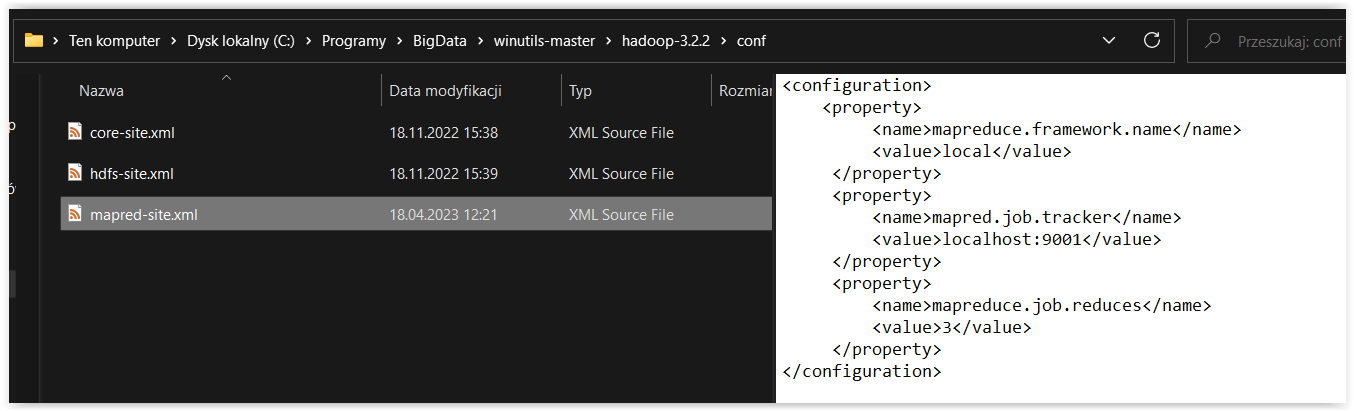
Jednak należy pamiętać, że

Zatem pozostaje nam alternatywa polegająca na określeniu liczby reduktorów podczas konfiguracji zadania MapReduce.
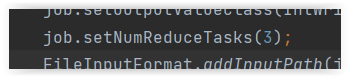
Zdecydowanie zalecam dokonanie korekty tego elementu, aby lepiej odwzorować rozproszone działania, które mają miejsce w klastrze Hadoop.